.svg)



ATLASSIAN
Sandbox Migration Event Logs
How redesigning Atlassian’s sandbox debug experience helped reduce support friction by 50%
Role
Product Designer
Team
1 Senior Designer, 1 Lead Developer, 1 Product Manager
Key Responsibilities
- Own end-to-end redesign of internal debug tool to reduce support friction
- Conduct task-based usability testing and developer interviews to inform UX
- Use information hierarchy and progressive disclosure to simplify complex logs
- Pair closely with engineers to implement reusable interaction patterns
- Leverage Atlassian design system for consistency and extensibility
- Enable cross-tool adoption of design through scalable UI components
background
When enterprise customers sandboxes fail, support engineers are required to troubleshoot.
Enterprise customers at Atlassian use sandboxes to safely test product changes, configurations, and app behaviors in isolated, non-production environments.
These sandboxes are critical for de-risking changes before deployment — especially in regulated industries where a single misstep can have major consequences. When customers are ready, they can migrate changes from sandbox to production.
But when something goes wrong during that migration — whether data fails to transfer, apps don’t behave as expected, or settings don’t persist — customers raise support tickets.
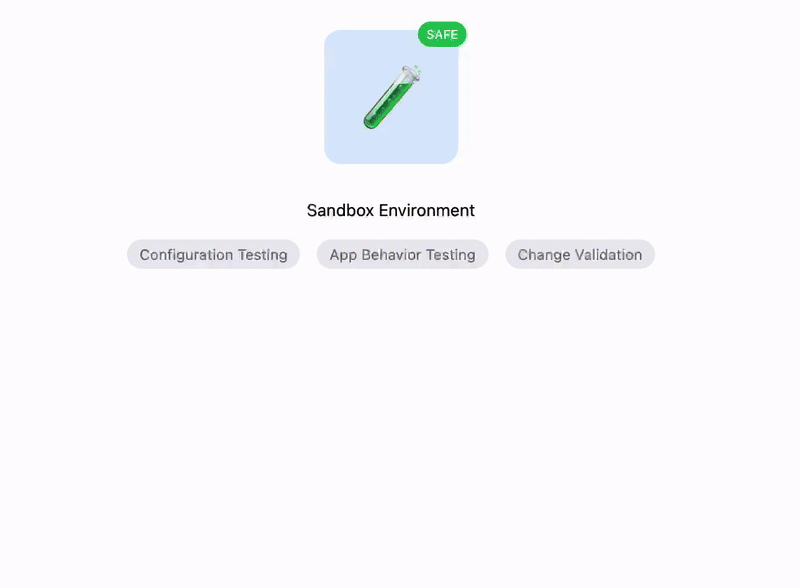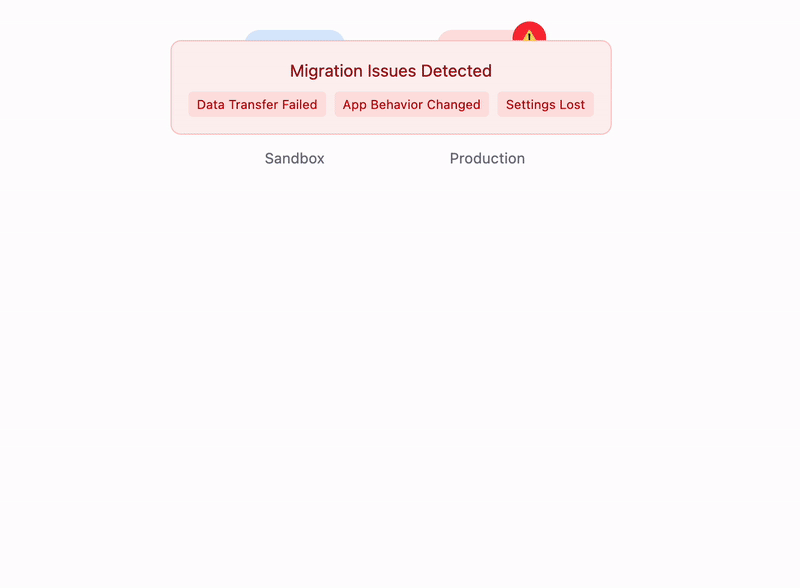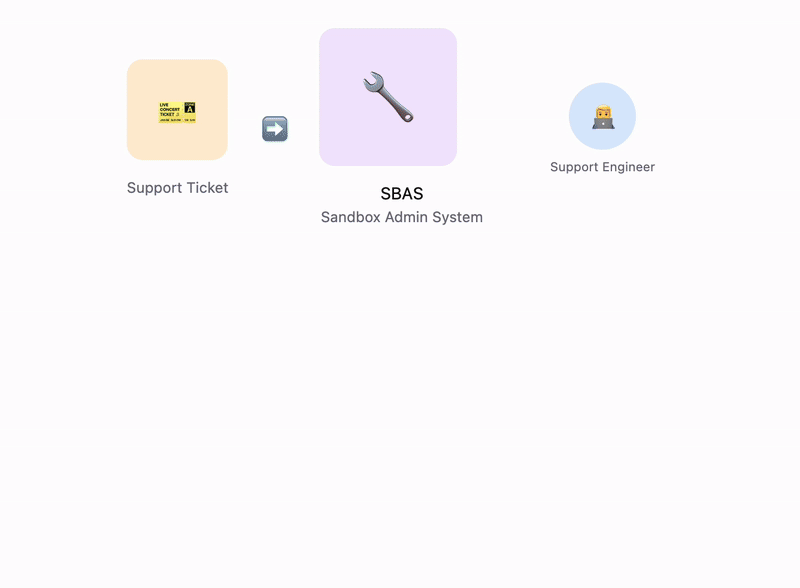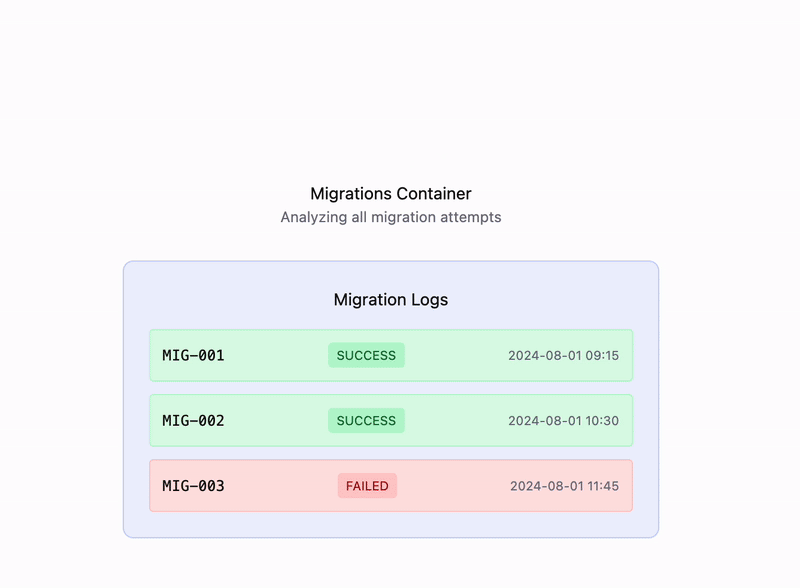
These tickets land with Atlassian’s internal support engineers, who turn to the Sandbox Admin System (SBAS) to troubleshoot. A core part of SBAS is the Sandbox Migrations Container, which lists all migration attempts.

problem
Engineers are relying on raw JSON logs to diagnose
Until recently, this view surfaced only raw JSON logs — unstructured, dense, and lacking context. Engineers had to manually dig through data dumps to identify root causes, often while juggling multiple tools, logins, and time zones.
For routine tickets, the process was tolerable. But when migrations failed in more complex ways, resolutions could stretch into days — frustrating developers and threatening enterprise trust.
SOLUTION
Enabling faster diagnosis, smoother support, and higher confidence in Atlassian’s enterprise cloud platform.
A redesigned Migrations Container that transformed raw logs into structured, actionable insight — enabling faster diagnosis, smoother support, and higher confidence in Atlassian’s enterprise cloud platform.
Solution
Update In Progress
01
Hi! I am currently updating this solution breakdown to reflect my current skill set.
Check out below for the previous version, or tune into my updated Macquarie and Pearler case studies!
...
impact
Improving customer experience, user experience and faciliatating cloud adoption
01
Reduced support friction by 50%, improving developer productivity and resolution speed.
02
Sparked internal adoption across adjacent tools spreading a new visual and interaction standard
03
Created task-specific clarity for support engineers under pressure replacing noisy data dumps with structured insight
04
Enabled a reusable pattern (e.g., header bars, “tabs-as-filters”) that shaped future internal tooling
05
Gave enterprise customers faster, more reliable sandbox support contributing to cloud platform satisfaction
Learnings
Ask more, ask often
- Collaborating async made me better at storytelling and documentation
- User testing with real tasks helped me prioritise qualitative insights over quantitative noise
-I learned how to work with uncertainty, without a PM or researcher — and still deliver value
- And I began to see how “small tools” like SBAS can quietly power trust at an enterprise scale
“Design isn’t just about making something usable. It’s about making it usable when it matters most.”
Process
How research, exploration, and iteration shaped the product foundation
Problem
Developers Were Debugging with a Blunt Instrument
Atlassian’s Sandbox Admin System (SBAS) supports engineers who troubleshoot issues for enterprise and premium customers testing changes in isolated environments.
A key component of this system — the Sandbox Migrations Container — lists all data copies and migration attempts from sandbox to production. However, this logs simply surfaced a raw JSON file, exposing success and failure events in a flat, unstructured dump.
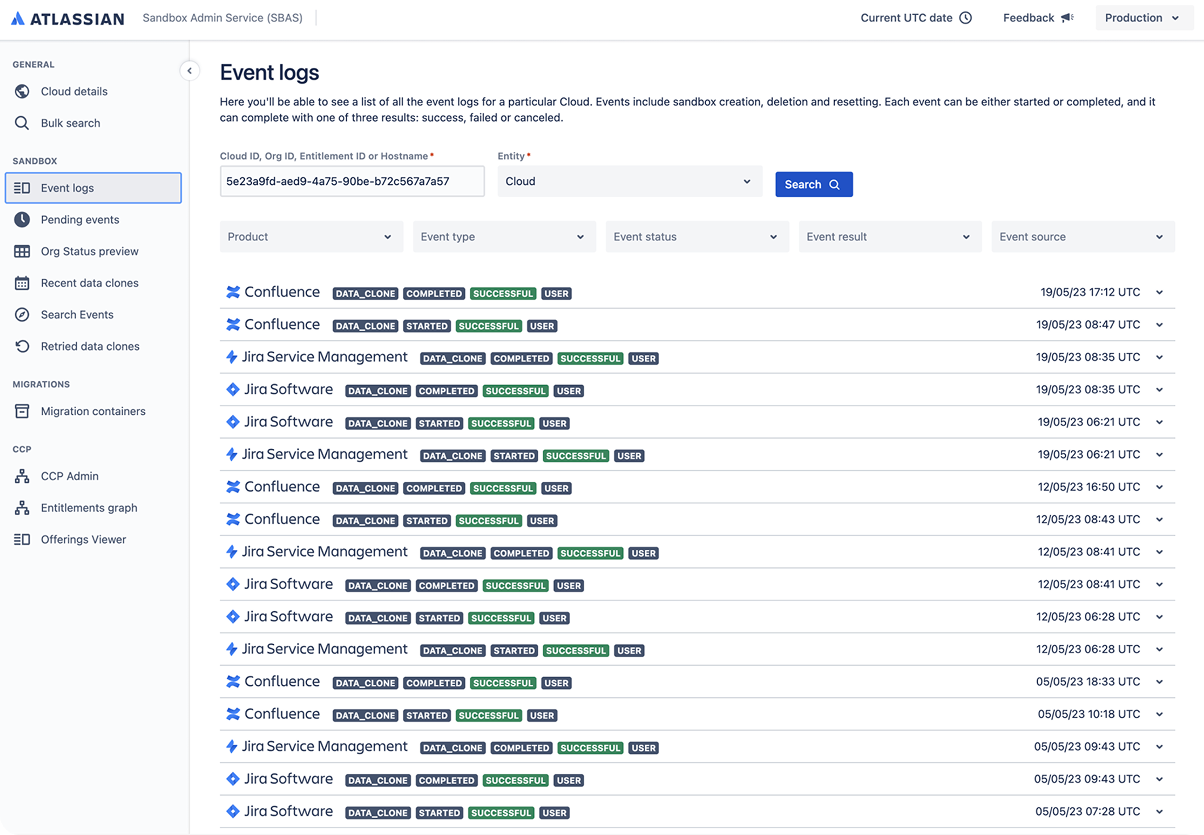
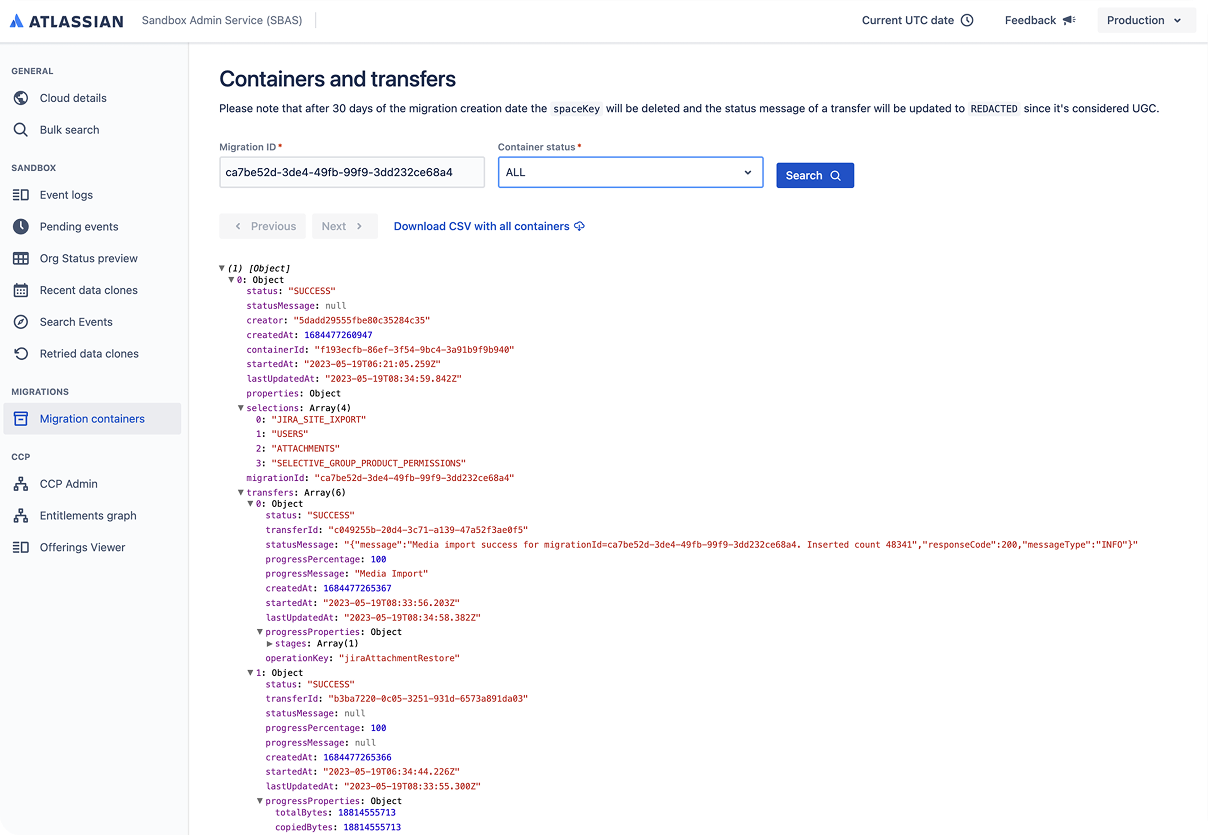
This made diagnosing failed migrations difficult and inefficient, especially under time pressure. The lack of grouping, hierarchy, or prioritization meant developers had to manually parse complex data with no contextual guidance.
“Right now I have to manually go to the audit logs and enter the migration ID myself. If that was available directly in the event log, it’d save a lot of time.”
What was at stake:
Slower support ticket resolution
Developer frustration
Risk to enterprise trust and satisfaction
The Setup
No PM, No Researchers — Just Me, Devs & Docs
When I joined the project, our product manager had just left.
I worked with:
🧑💻 Lead developer: Weekly async design reviews
👩🎨 Senior designer: Ad hoc syncs every 2–3 days
🧠 Design crit team: Fortnightly formal sessions
📜 Historical research: Inherited documentation as my foundation
With no dedicated UX researcher, I ran my own usability testing and leaned into developer interviews, async walkthroughs, and user quotes to shape direction.
User Research
Developers Wanted Less Noise, More Signal
I conducted task-based usability testing with 7 engineers using high-fidelity Figma prototypes. Each participant completed 2 tasks:
1) Identify a sandbox issue,
2) Troubleshoot the issue.
Each task had a 100% success rate, and had SEQ scores of >5 out of 7 indicating satisfaction with room for improvement.
Pain points uncovered:
Developers had a mental model of single sandbox use — new multi-sandbox support caused confusion
Cognitive load was high due to duplicated information across platforms
Auth friction was high — engineers had to log in multiple times to retrieve basic data
Exploration & Iteration:
Designing for Speed Under Pressure
My design goals:
Information hierarchy — no more data dumps
Progressive disclosure — reduce visual overload
Traceability — grouping events by sandbox

Design system use:
Used Atlassian’s patterns for tables, badges, alignment, tabs
Collaborated with a senior designer to co-create header patterns for extensibility, and collaborated with another designer to understand my side panel implementation
The "Tabs as Filters" Decision: In an early iteration, I used tabs to let users toggle views by status (e.g. Failed, Success). While unconventional, the small dev team appreciated this as a “saved view” — a junior call that turned into a surprisingly sticky pattern.
Results
Support Just Got 50% Easier
- Support engineers now had clearer, faster visibility into what went wrong and where
- They could identify root causes faster, cutting cognitive effort
- Several other internal tools began adopting this redesigned pattern — indicating organic system spread
📉 Hypothesised outcome:
50% reduction in support friction (based on internal feedback)
Quicker resolutions → higher developer productivity → happier customers